Вопрос 7: Виды селекции в генетическом алгоритме.
Зависимые вопросы
- Вопрос 5: Генетический алгоритм. Определение. Общая схема. Понятие хромосомы, гена, отбора.
- Вопрос 6: Виды кроссовера в генетическом алгоритме.
- Вопрос 8: Бинарное и вещественное кодирование в генетическом алгоритме. Код Грея.
- Вопрос 9: Понятие элитизма. Алгоритм островов. Клеточный ГА.
Определения
Селекция - это оператор, посредством которого индивиды (т.е. хромосомы) выбираются для спаривания и порождения потомков.
Для имитации естественной селекции индивиды с более высокой пригодностью должны выбираться с большей вероятностью.
Существует большое число различных моделей селекции, некоторые из которых не имеют биологических аналогов.
Большинство схем селекций, используемых в ГА, создают промежуточную популяцию и затем выбирают из нее случайным образом пары индивидов для скрещивания.
Предположения:
- Мера Q качества решения (целевая функция) задачи известна.
- Она должна быть максимизирована.
- Она должна быть всегда положительной.
- Мы рассматриваем меру Q качества индивида как его пригодность.
Рулеточная селекция
Рулеточный отбор - метод селекции считается для генетических алгоритмов основным методом отбора особей для родительской популяции с целью последующего их преобразования генетическими операторами, такими как скрещивание и мутация.
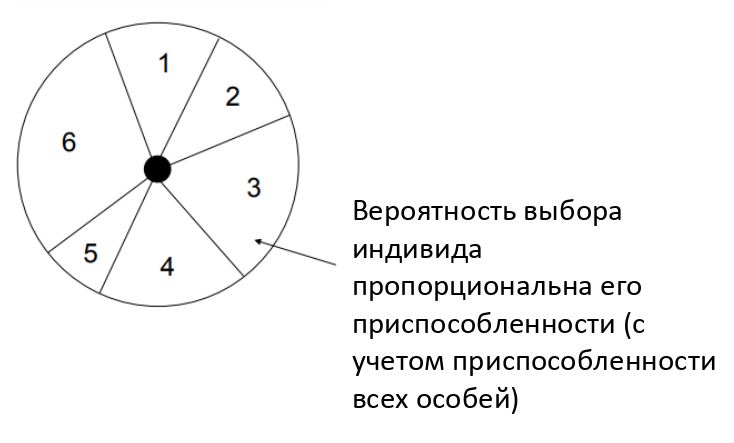
Несмотря на случайный характер процедуры селекции, родительские особи выбираются пропорционально значениям их функций приспособленности:
каждой хромосоме сопоставлен сектор колеса рулетки, величина которого устанавливается пропорциональной значению функции приспособленности данной хромосомы, поэтому, чем больше значение функции приспособленности, тем больше сектор на колесе рулетки.
Из такого метода вытекает следующее:
чем больше сектор на колесе рулетки, тем выше шанс, что будет выбрана именно эта хромосома.
Слабая сторона этого метода заключается в том, что особи с очень малым значением функции приспособленности слишком быстро исключаются из популяции, что может привести к преждевременной сходимости генетического алгоритма.
Пропорциональная селекция
- пригодность индивида
- средняя пригодность популяции.
Два условия выбора индивида :
- большая вероятность .
- выбирать случайное вещественное число и отобрать того индивида, для которого .
Проблема: такой алгоритм работает относительно медленно.
В равновесном ГА популяциям не разрешается увеличиваться или сокращаться, поэтому для репродукции отбирают индивидов. Отсюда следует, что ожидаемое число копий каждого индивида в промежуточной популяции равно .
обычно является вещественным числом. Реальное число копий (целое) может варьироваться около .
Индивиды с пригодностью выше средней имеют более одной копии в промежуточной популяции, а индивиды ниже средней пригодности могут не иметь ни одной (в среднем).
Проблемы с пропорциональной селекцией:
- Преждевременная сходимость:
- Индивид с был получен на ранних поколениях.
- Так как , гены такого индивида довольно быстро распространятся на всю популяцию.
- В таком случае рекомбинация не может более производить новых индивидов (только мутация может) и навсегда.
- Стагнация:
- Ближе к концу работы алгоритма все индивиды могут получить относительно высокую и примерно равную пригодность, т.е. .
- Тогда , что приводит к очень маленькому селективному давлению, т.е. наилучшее решение предпочитается лишь немного больше, чем наихудшее.
Ранговая селекция
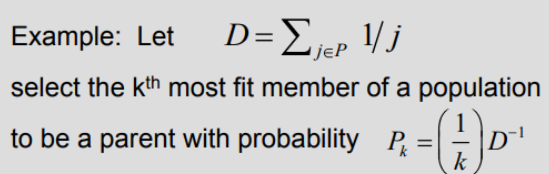
- Индивиды сортируются (ранжируются) на основе их пригодности таким образом, чтобы .
- Затем каждому индивиду назначается вероятность быть отобранным, взятая из заданного распределения с ограничением .
Типичные распределения:
- Линейное: .
- Отрицательное экспоненциальное: . Это эквивалентно назначению первому индивиду вероятности p, второму - , третьему - , и т.д.
Преимущества:
- Нет преждевременной сходимости, т.к. нет индивидов с .
- Нет стагнации, так как и к концу работы алгоритма .
- Нет необходимости в явном вычислении пригодности, т.к. для упорядочения индивидов достаточно иметь возможность их попарного сравнения.
- Возможность применения как для максимизации, так и для минимизации функции.
Недостатки:
- Значительные накладные расходы на переупорядочивание.
- Трудность теоретического анализа сходимости.
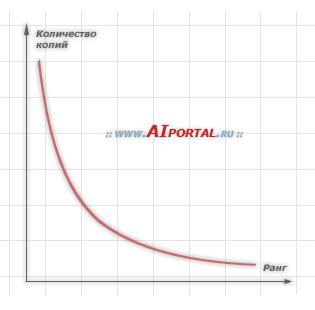
График зависимости количества копий особей в популяции от ранга каждой особи:
Турнирная селекция
Для отбора индивида создается группа из индивидов, выбранных случайным образом
Индивид с наибольшей пригодностью в группе отбирается, остальные - отбрасываются (турнир)
Турнирную селекцию можно рассматривать как ранговую селекцию при наличии шума.
Преимущества:
- Нет преждевременной сходимости
- Нет стагнации
- Не требуется глобальное переупорядочивание
- Не требуется явное вычисление функции пригодности
Элитарная селекция
Разбирается в вопросе 9: Понятие элитизма. Алгоритм островов. Клеточный ГА.
Как минимум одна копия лучшего индивида популяции всегда проходит в следующее поколение.
Преимущество: гарантия сходимости, т.е. если глобальный максимум будет обнаружен, то ГА сойдется к этому максимуму
Недостаток: большой риск захвата локальным минимумом
Альтернатива: сохранять лучшую найденную структуру в специальной ячейке памяти и в конце эксперимента использовать ее в качестве решения вместо лучшего в последнем поколении.